В путь...
На старт, внимание, марш!
 Отлично, давайте начнем! Если вы из тех ужасных людей, что не читают введение и просто пропускают его, то вам все равно стоит заглянуть в его заключительную часть, так как именно там объясняется то, что вам потребуется при прочтении данного руководства и что необходимо для загрузки программ.
Первое, что мы сделаем – это запустим GHC в интерактивном режиме, и вызовем несколько функций, чтобы почувствовать Haskell. Откройте консоль и наберите ghci. Вы увидите примерно такое приветствие:
Отлично, давайте начнем! Если вы из тех ужасных людей, что не читают введение и просто пропускают его, то вам все равно стоит заглянуть в его заключительную часть, так как именно там объясняется то, что вам потребуется при прочтении данного руководства и что необходимо для загрузки программ.
Первое, что мы сделаем – это запустим GHC в интерактивном режиме, и вызовем несколько функций, чтобы почувствовать Haskell. Откройте консоль и наберите ghci. Вы увидите примерно такое приветствие:
GHCi, version 6.8.2: http://www.haskell.org/ghc/ :? for help Loading package base ... linking ... done. Prelude>
Поздравляю, вы в GHCi! Приглашение консоли ввода – Prelude>но поскольку оно может меняться процессе работы, мы будем использовать просто ghci>. Если вы захотите, чтобы у вас было такое же приглашение – наберите команду :set prompt "ghci> ".
Немного школьной арифметики.
ghci> 2 + 15 17 ghci> 49 * 100 4900 ghci> 1892 - 1472 420 ghci> 5 / 2 2.5 ghci>
Код говорит сам за себя. Также, в одной строке мы можем использовать несколько операторов, при этом работает обычный порядок вычислений. Можно также использовать круглые скобки для облегчения читаемости кода или для изменения порядка вычислений.
ghci> (50 * 100) - 4999 1 ghci> 50 * 100 - 4999 1 ghci> 50 * (100 - 4999) -244950
Здорово, да? Да, я знаю, что это не так, но немного терпения. Небольшая опасность кроется в использовании отрицательных чисел. Если нам захочется использовать отрицательные числа, то всегда лучше обернуть их в скобки. Попытка выполнения 5 * -3 заставит GHCI визжать, но 5 * (-3) будет работать просто замечательно.
Булева алгебра также очень прямолинейна. Как вы, возможно, знаете, && – означает логическое and, || – логическое or. not – логическое отрицание.
ghci> True && False False ghci> True && True True ghci> False || True True ghci> not False True ghci> not (True && True) False
Проверка на равенство делается так:
ghci> 5 == 5 True ghci> 1 == 0 False ghci> 5 /= 5 False ghci> 5 /= 4 True ghci> "hello" == "hello" True
А как насчет 5 + "llama" или 5 == True? Так, если мы попробуем выполнить первый фрагмент, то получим большое и страшное сообщение об ошибке!
No instance for (Num [Char]) arising from a use of `+' at <interactive>:1:0-9 Possible fix: add an instance declaration for (Num [Char]) In the expression: 5 + "llama" In the definition of `it': it = 5 + "llama"
Ой! GHCi говорит нам, что "llama" не является числом, и он (GHCi) не знает, как это прибавить к 5. Даже если бы это было не "llama" , а "four" или "4", то Haskell все равно не считал бы это числом. + ожидает, что аргументы слева и справа будут числовыми. Если же мы попытаемся посчитать True == 5, GHCi скажет нам, что типы не совпадают. Несмотря на то, что + оперирует только с такими элементами, которые можно воспринять как число, == же, напротив, с любой парой, которую можно сравнить, но фокус в том, что они должны быть одного типа. Вы не сможете сравнить яблоки и апельсины. Подробнее мы рассмотрим это чуть позже. Замечание: вы сможете посчитать 5 + 4.0, потому что 5 может вести себя как целое число или как число с плавающей точкой. 4.0 не может выступать в роли целого числа, поэтому 5 должно подстроиться.
Возможно, вы ещё не поняли, но всё это время мы использовали функции. Например, * это функция, которая принимает два числа и перемножает их. Как вы видели, мы вызываем её, вставляя * между числами. Это называется инфиксная функция. Большинство функций, используемых не с числами – префиксные функции. Давайте рассмотрим их.
 Функции обычно префиксные, поэтому с этого момента мы не будем явно указывать, что функция имеет префиксную форму, а будем это подразумевать. В большинстве императивных языков функции вызываются указанием имени функции, а затем – её аргументов в скобках, обычно, разделенных запятыми. В Haskell функции вызываются указанием имени функции, пробела и затем параметров, разделенных пробелами. Для начала, попробуем вызвать одну из самых скучных функций языка.
Функции обычно префиксные, поэтому с этого момента мы не будем явно указывать, что функция имеет префиксную форму, а будем это подразумевать. В большинстве императивных языков функции вызываются указанием имени функции, а затем – её аргументов в скобках, обычно, разделенных запятыми. В Haskell функции вызываются указанием имени функции, пробела и затем параметров, разделенных пробелами. Для начала, попробуем вызвать одну из самых скучных функций языка.
ghci> succ 8 9
Функция succ принимает всё, что имеет определенное последующее значение и затем возвращает его. Как вы видите, мы отделяем имя функции от параметра просто пробелом. Вызывать функции с несколькими параметрами также очень просто. Функции min и max принимают по два аргумента, которые можно упорядочивать (как и числа!). min возаращает наименьшее, а max возвращает наибольшее. Убедитесь сами:
ghci> min 9 10 9 ghci> min 3.4 3.2 3.2 ghci> max 100 101 101
Применение функции (вызов функции с пробелом после неё и списком параметров) имеет наивысший приоритет. Для нас это значит, что следующие два выражения эквивалентны.
ghci> succ 9 + max 5 4 + 1 16 ghci> (succ 9) + (max 5 4) + 1 16
Однако, если мы хотим получить последующее значение от произведения чисел 9 и 10, мы не можем написать succ 9 * 10 , потому что это даст последующее значение за 9, которое будет умножено на 10. То есть, 100. Нам надо написать succ (9 * 10), чтобы получить 91.
Если функция принимает два параметра, мы также можем вызвать её в инфиксной форме, окружив её имя обратными апострофами. Например, функция div принимает два челых числа и выполняет их целочисленное деление. Выполнение div 92 10 возвращает 9. Но если мы вызываем её так, то может возникнуть некоторое недопонимание, какое из чисел – делимое, а какое – делитель. Поэтому мы можем вызвать функцию в инфиксной форме: 92 `div` 10, что, как оказывается, гораздо понятнее.
Многие люди, пришедшие с императивных языков, обычно, придерживаются мнения, что применение функции должно обозначаться скобками. Например, в Си используются скобки для вызова функций вроде foo(), bar(1) или baz(3, "haha"). Как мы уже сказали, для применения функций в Haskell используются пробелы. Вызов этих функций в Haskell будет выглядеть как foo, bar 1 and baz 3 "haha". Так что, если вы увидите нечто вроде bar (bar 3), это не значит, что bar вызывается с параметрами bar и 3. Это значит, что мы сначала вызываем функцию bar с параметром 3 3чтобы получить некоторое число, а затем опять вызываем bar с этим числом в качестве параметра. В языке Си это выглядело бы как bar(bar(3)).
Первые функции малыша
В предыдущей секции мы получили общее представление о вызове функций. Давайте теперь создадим собственную функцию! Откройте свой любимый текстовый редактор и наберите такую функцию, принимающую число и умножающую его на 2.
doubleMe x = x + x
Определяются функции точно так же, как и вызываются. За именем функции следуют параметры, разделенные пробелами. Но при определении функции есть еще символ = и следом за ним описывается, что функция делает. Сохраните это, например, под именем baby.hsЗатем перейдите туда, куда вы это сохранили, и запустите GHCi оттуда. В GHCi выполните ghci from there. Once inside GHCI, do :l baby. Теперь наш скрипт загружен, и мы можем поиграться c функцией, которую мы определили.
ghci> :l baby [1 of 1] Compiling Main ( baby.hs, interpreted ) Ok, modules loaded: Main. ghci> doubleMe 9 18 ghci> doubleMe 8.3 16.6
Поскольку + работает как на целых числах, так и на числах с плавающей точкой (на самом деле, на всём, что может быть воспринято как число), поэтому наша функция одинаково хорошо работает с любыми числами. Давайте сделаем функцию, которая принимает два числа, умножает каждое на 2 и результат складывает.
doubleUs x y = x*2 + y*2
Все просто. Мы также могли определить эту функцию как doubleUs x y = x + x + y + y. . Если её потестировать — она выдает хорошо предсказуемые результаты (не забудьте дописать эту функцию в файл baby.hs, сохранить его и затем выполнить :l baby из GHCi).
ghci> doubleUs 4 9 26 ghci> doubleUs 2.3 34.2 73.0 ghci> doubleUs 28 88 + doubleMe 123 478
Вы можете вызывать свои собственные функции из других созданных вами же функций, что ожидаемо. Учитывая это, мы можем переопределить doubleUs как:
doubleUs x y = doubleMe x + doubleMe y
Это очень простой пример общего подхода, применяемого во всём языке – создавать простые базовые функции, корректность которых очевидна, и затем комбинировать из них более сложные. Подобный подход, также, позволяет избежать дублирования кода. Например, если какие-нибудь «математики» вывели бы, что 2 – это на самом деле 3 и вам нужно изменить свою программу? Вы бы могли просто переопределить doubleMe как x + x + x, и поскольку doubleUs вызывает doubleMe, она бы автоматически работала в этом странном мире, где 2 – это 3.
Функции в Haskell могут не следовать в каком-то определенном порядке, поэтому неважно, определите ли вы сначала doubleMe , а затем – doubleUs, или еще как-нибудь.
Теперь мы собираемся создать функцию, которая умножает число на 2, но только если оно меньше либо равно 100, потому что числа больше – слишком велики.
doubleSmallNumber x = if x > 100
then x
else x*2

Мы только что воспользовались условным оператором «if» в Haskell. Возможно, вы уже знакомы с условными операторами из других языков. Разница между оператором «if» из Haskell и операторами «if» из императивных языков в том, что в Haskell ветвь «else» является обязательной. В императивных же языках вы можете просто пропустить пару шагов, если условие не выполняется, а в Haskell каждое выражение или функция должны что-то возвращать. Мы можем написать оператор «if» в одну строку, но я считаю, что это не так читабельно. Еще один аспект условного оператора в Haskell – это то, что он является выражением. Выражение – это код, возвращающий значение. 5 – это выражение, потому что возвращает 5, 4 + 8– выражение, x + y – выражение, потому что оно возвращает сумму x и y. Поскольку ветвь «else» обязательна, оператор «if» всегда что-нибудь вернёт, поэтому он является выражением. Если бы мы хотели добавить единицу к любому значению, получившемуся в результате нашей предыдущей функции, мы могли бы написать её тело вот так:
doubleSmallNumber' x = (if x > 100 then x else x*2) + 1
Если бы мы опустили скобки, единица добавлялась бы только если x не больше 100. Обратите внимание на ' в конце имени функции. Этот апостроф не имеет какого-либо специального значения в языке Haskell. Это допустимый символ для использования в имени функции. Обычно мы используем ' (апостроф) для обозначения строгой (не ленивой) версии функции, либо для слегка модифицированной версии функции или переменной. Поскольку ' – допустимый символ в функциях, то мы можем делать такие функции:
conanO'Brien = "It's a-me, Conan O'Brien!"
Здесь следует обратить внимание на две важные особенности. Первая – то, что в имени функции мы не пишем Conan с заглавной буквы. Это потому, что функции не могут начинаться с заглавной буквы. Чуть позже мы разберёмся, почему. Вторая – данная функция не принимает никаких параметров. Когда функция не принимает аргументов, говорят, что это определение (или имя). Поскольку мы не можем изменить содержание имён (и функций) после того, как их определили conanO'Brien и строка "It's a-me, Conan O'Brien!" могут использоваться взаимозаменяемо.
Введение в списки
 Как и списки покупок в реальном мире, списки в Haskell очень полезны. Это наиболее часто используемая структура данных, и ее можно испольщовать различными способами, для описания и решения целой кучи проблем. Списки ТАКИЕ потрясающие! В этой секции мы посмотрим на основы работы со списками, строками (что тоже являются списками) и «выражениями списков».
Как и списки покупок в реальном мире, списки в Haskell очень полезны. Это наиболее часто используемая структура данных, и ее можно испольщовать различными способами, для описания и решения целой кучи проблем. Списки ТАКИЕ потрясающие! В этой секции мы посмотрим на основы работы со списками, строками (что тоже являются списками) и «выражениями списков».
В Haskell списки – это гомогенные структуры данных. Они содержат несколько элементов одного типа. Это значит, что может быть список целых или список символов, но не может быть списка с несколькими целыми значениями и несколькими символами. А теперь, список!
ghci> let lostNumbers = [4,8,15,16,23,42] ghci> lostNumbers [4,8,15,16,23,42]
Как вы видите, списки обозначаются квадратными скобками, а значения в списках разделяются запятыми. Если попытаться создать список вроде [1,2,'a',3,'b','c',4], Haskell пожалуется, что символы (которые, кстати, указываются как символы между одиночными кавычками) – это не числа. Кстати, о символах: строки – это списки символов. "hello"– это синтаксический сахар для ['h','e','l','l','o'].Поскольку строки – это списки, мы можем использовать для них функции для работы со списками, что очень удобно.
Обычная задача – объединение двух списков. Это делается с помощью оператора ++.
ghci> [1,2,3,4] ++ [9,10,11,12] [1,2,3,4,9,10,11,12] ghci> "hello" ++ " " ++ "world" "hello world" ghci> ['w','o'] ++ ['o','t'] "woot"
Будьте осторожны при использовании оператора ++ с длинными строками. Если вы объединяете два списка (даже если вы дописываете в конец списка список из одного элемента, например, [1,2,3] ++ [4]), то Haskell должен обойти весь список с левой стороны от ++. Это не проблема, когда обрабатываются небольшие списки, но добавление к концу списка из 50000000 элементов займёт много времени. Однако, если добавить что-нибудь в начало списка с помощью оператора : (также называемым оператором cons), то это будет моментально.
ghci> 'A':" SMALL CAT" "A SMALL CAT" ghci> 5:[1,2,3,4,5] [5,1,2,3,4,5]
Обратите внимание, что функция : принимает число и список чисел или символ и список символов, в то время как ++ принимает два списка. Даже если вы добавляете элемент в конец списка с помощью ++, вы должны обернуть этот элемент в квадратные скобки, чтобы он стал списком.
[1,2,3] – это на самом деле синтаксический сахар над 1:2:3:[]. [] это пустой список и если мы добавим к его началу 3 получится [3], а если к этому мы еще добавим в начало 2, получится [2,3], и так далее.
Примечание: [], [[]] and[[],[],[]] — разные типы. Первое – это пустой список, второе – список, содержащий один пустой список, а третье – список, содержащий три пустых списка.
Если вы хотите извлечь элемент из списка по индексу, используйте !!. Индексы начинаются с нуля.
ghci> "Steve Buscemi" !! 6 'B' ghci> [9.4,33.2,96.2,11.2,23.25] !! 1 33.2
Но если вы попытаетесь получить шестой элемент списка, состоящего из четырёх элементов, вы получите ошибку, так что будьте осторожны!
Списки также могут содержать списки. Также они могут содержать списки, которые содержат списки, которые содержат списки …
ghci> let b = [[1,2,3,4],[5,3,3,3],[1,2,2,3,4],[1,2,3]] ghci> b [[1,2,3,4],[5,3,3,3],[1,2,2,3,4],[1,2,3]] ghci> b ++ [[1,1,1,1]] [[1,2,3,4],[5,3,3,3],[1,2,2,3,4],[1,2,3],[1,1,1,1]] ghci> [6,6,6]:b [[6,6,6],[1,2,3,4],[5,3,3,3],[1,2,2,3,4],[1,2,3]] ghci> b !! 2 [1,2,2,3,4]
Списки внутри списка могут быть разной длины, но не могут быть разных типов. Так же как нельзя создать список, содержащий несколько символов и несколько чисел, нельзя создать список, содержащий несколько списков символов и несколько списков чисел.
Списки можно сравнить, если можно сравнить их элементы. Когда используются операторы <, <=, > и >=для сравнения списков, они сравниваются в лексикографическом порядке. Сначала сравниваются головные элементы, если они равны, сравниваются вторые элементы и так далее.
ghci> [3,2,1] > [2,1,0] True ghci> [3,2,1] > [2,10,100] True ghci> [3,4,2] > [3,4] True ghci> [3,4,2] > [2,4] True ghci> [3,4,2] == [3,4,2] True
Что ещё можно делать со списками? Вот несколько основных функций работы со списками.
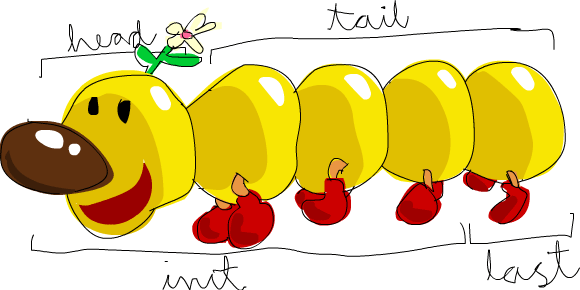
head принимает список и возвращает его головной элемент. Головной элемент списка – это, собственно, его первый элемент.
ghci> head [5,4,3,2,1] 5
tail принимает список и возвращает его хвост. Иными словами, эта функция отрезает голову списка.
ghci> tail [5,4,3,2,1] [4,3,2,1]
last принимает список и возвращает его последний элемент.
ghci> last [5,4,3,2,1] 1
init принимает список и возвращает всё, кроме его последнего элемента.
ghci> init [5,4,3,2,1] [5,4,3,2]
Если представить список как монстра, то вот что есть что.
Но что будет, если мы попытаемся получить головной элемент пустого списка?
ghci> head [] *** Exception: Prelude.head: empty list
Боже мой! Всё сломалось! Если нет монстра, у него нет головы. При использовании head, tail, last и init, будьте осторожны и не используйте их для пустых списков. Эту ошибку нельзя отловить на этапе компиляции, так что всегда полезно принять меры против случайных попыток попросить Haskell выдать несколько элементов из пустого списка.
length , очевидно, принимает список и возвращает его длину.
ghci> length [5,4,3,2,1] 5
null проверяет, не пуст ли список. Если пуст, функция возвращает True, иначе она возвращает False. Используйте эту функцию вместо xs == [] (если у вас есть список с именем xs)
ghci> null [1,2,3] False ghci> null [] True
reverse обращает список (расставляет его элементы в обратном порядке).
ghci> reverse [5,4,3,2,1] [1,2,3,4,5]
take принимает число и список. Эта функция извлекает некое количество элементов из начала списка, соответствующее числовому параметру. Смотрите:
ghci> take 3 [5,4,3,2,1] [5,4,3] ghci> take 1 [3,9,3] [3] ghci> take 5 [1,2] [1,2] ghci> take 0 [6,6,6] []
Обратите внимание, что если попытаться получить больше элементов, чем есть в списке, функция возвращает весь список. Если мы пытаемся получить 0 элементов, функция возвращает пустой список.
drop работает сходным образом, но отрезает указанное количество элементов с начала списка.
ghci> drop 3 [8,4,2,1,5,6] [1,5,6] ghci> drop 0 [1,2,3,4] [1,2,3,4] ghci> drop 100 [1,2,3,4] []
maximumпринимает список чего-либо, что можно упорядочить, и возвращает наибольший элемент.
minimum возвращает наименьший элемент.
ghci> minimum [8,4,2,1,5,6] 1 ghci> maximum [1,9,2,3,4] 9
sum принимает список чисел и возвращает их сумму.
product принимает список чисел и возвращает их произведение.
ghci> sum [5,2,1,6,3,2,5,7] 31 ghci> product [6,2,1,2] 24 ghci> product [1,2,5,6,7,9,2,0] 0
elem принимает элемент и список элементов и проверяет, входит ли элемент в список. Обычно эта функция вызывается как инфиксная, поскольку так проще её читать.
ghci> 4 `elem` [3,4,5,6] True ghci> 10 `elem` [3,4,5,6] False
Это были несколько основных функций для работы со списками. Мы упомянем еще несколько в секции позже
Texas ranges *
* Название дословно переводится как "Техасские диапазоны". Ranges (диапазон) и Rangers (рейнджеры) звучат похоже, что создает шуточную атмосферу.
 Что если нам нужен список всех чисел от 1 до 20? Конечно, мы могли бы просто вбить их все, но очевидно, это не решение для джентльмена, требующего совершенства от языка программирования. Вместо этого, мы будем использовать диапазоны. Ряды – это способ создания списков, являющихся арифметическими последовательностями элементов, которые могут быть перечислены. Один, два, три, четыре и т.д. Символы тоже могут быть перечислены. Алфавит – это перечисление символов от A до Z. Имена не могут быть перечислены. Что будет идти после «John»? Мне не известно.
Что если нам нужен список всех чисел от 1 до 20? Конечно, мы могли бы просто вбить их все, но очевидно, это не решение для джентльмена, требующего совершенства от языка программирования. Вместо этого, мы будем использовать диапазоны. Ряды – это способ создания списков, являющихся арифметическими последовательностями элементов, которые могут быть перечислены. Один, два, три, четыре и т.д. Символы тоже могут быть перечислены. Алфавит – это перечисление символов от A до Z. Имена не могут быть перечислены. Что будет идти после «John»? Мне не известно.
Чтобы сделать список, содержащий все натуральные числа от 1 до 20, надо написать [1..20]. Это эквивалентно [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20], и единственная разница между первым и вторым – то, что писать перечисление длинной последовательности вручную глупо.
ghci> [1..20] [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20] ghci> ['a'..'z'] "abcdefghijklmnopqrstuvwxyz" ghci> ['K'..'Z'] "KLMNOPQRSTUVWXYZ"
Диапазоны замечательны, поскольку можно указать шаг. Что если мы хотим все чётные числа от 1 до 20? Или каждое третье число от 1 до 20?
ghci> [2,4..20] [2,4,6,8,10,12,14,16,18,20] ghci> [3,6..20] [3,6,9,12,15,18]
Нужно всего лишь разделить первые два элемента последовательности запятой и указать верхнюю границу. Хотя диапазоны достаточно «умны», они не настолько умны, как ожидают «некоторые». Вы не можете написать [1,2,4,8,16..100] и после этого ожидать, что получите все степени двойки. Во-первых, потому что можно указать только один шаг. А во-вторых, потому что некоторые последовательности, не являющиеся арифметическими, неоднозначны, если представлены только первыми несколькими элементами.
Чтобы создать список со всеми числами от 20 до 1, вы не можете просто написать [20..1], а должны написать [20,19..1].
Будьте осторожны при использовании чисел с плавающей точкой в диапазонах! Из-за того, что они не совсем точны (по определению), их использование в диапазонах может привести к весьма забавным результатам.
ghci> [0.1, 0.3 .. 1] [0.1,0.3,0.5,0.7,0.8999999999999999,1.0999999999999999]
Мой совет: не используйте их в диапазонах.
Диапазоны, также, можно использовать для создания бесконечных списков, просто не указывая верхний предел. Позже мы рассмотрим их более детально. А сейчас давайте посмотрим, как можно получить список первых 24 чисел, кратных 13. Конечно, вы могли бы написать [13,26..24*13]. Но есть способ лучше: take 24 [13,26..]. Поскольку Haskell ленив, он не будет пытаться немедленно вычислить бесконечный список, потому что процесс никогда не завершится. Он подождёт, пока вы не захотите получить чот-либо из такого списка. И тут он видит, что вы хотите получить только первые 24 элемента и он с радостью подчиняется.
Немного функций, производящих бесконечные списки:
cycle принимает список и зацикливает его в бесконечный. Если вы попробуете отобразить результат, то на это уйдет вечность, поэтому вам придётся где-то его обрезать.
ghci> take 10 (cycle [1,2,3]) [1,2,3,1,2,3,1,2,3,1] ghci> take 12 (cycle "LOL ") "LOL LOL LOL "
repeat принимает элемент и возвращает бесконечный список, состоящий только из этого элемента. Это вроде как зациклить список из одного элемента.
ghci> take 10 (repeat 5) [5,5,5,5,5,5,5,5,5,5]
Однако, проще использовать функцию replicate, если вам нужен список из некоторого количества одинаковых элементов. replicate 3 10 вернёт [10,10,10].
Я - выражение списков.
 Если вы изучали курс математики, возможно, уже сталкивались со способом задания множеств описанием характеристических свойств, которыми должны обладать его элементы. Обычно используются для построения подмножеств из множеств. Пример простого описания множества – множество, состоящее из первых десяти чётных чисел это:
Если вы изучали курс математики, возможно, уже сталкивались со способом задания множеств описанием характеристических свойств, которыми должны обладать его элементы. Обычно используются для построения подмножеств из множеств. Пример простого описания множества – множество, состоящее из первых десяти чётных чисел это: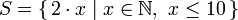 где выражение перед вертикальной линией называется производящей функцией (output function), x – переменная, N – входной набор, а x <= 10 – предикат. Это означает, что множество содержит удвоенные натуральные числа, которые удовлетворяют предикату.
где выражение перед вертикальной линией называется производящей функцией (output function), x – переменная, N – входной набор, а x <= 10 – предикат. Это означает, что множество содержит удвоенные натуральные числа, которые удовлетворяют предикату.
Если бы нам потребовалось написать это на языке Haskell, то можно сделать что-то вроде take 10 [2,4..]. Но что если мы хотим получить не просто первые десять удвоенных натуральных чисел, а применить к ним некую более сложную функцию? Для этого можно использовать «выражение списка». «Выражение списков» очень похоже на описание множеств. Остановимся на получении первых 10 чётных чисел. «Выражение списка», которое мы можем использовать – [x*2 | x <- [1..10]]. x берется из [1..10], и для каждого элемента из [1..10] (диапазон, который мы привязали к x), мы берем этот элемент, только умноженный на 2. Вот это «выражение» в действии.
ghci> [x*2 | x <- [1..10]] [2,4,6,8,10,12,14,16,18,20]
Как вы видите, мы получили желаемые результаты. Теперь давайте добавим условие (или предикат) к этому выражению. Предикаты идут после присваивающей части и отделяются от неё запятой. Давайте скажем, что нам нужны только те элементы, которые, будучи удвоенными, больше либо равны 12.
ghci> [x*2 | x <- [1..10], x*2 >= 12] [12,14,16,18,20]
Это работает, замечательно. А как насчет ситуации, если б мы захотели получить все числа от 50 до 100, остаток от деления на 7 которых равен 3? Легко!
ghci> [ x | x <- [50..100], x `mod` 7 == 3] [52,59,66,73,80,87,94]
Получилось! Заметим, что прорежение списков с помощью предикатов также называется фильтрацией. Мы взяли список чисел и отфильтровали их предикатами. Теперь другой пример. Давайте предположим, что нам нужно выражение, которое заменяет каждое нечётное число больше 10 на "BANG!" , а каждое нечетное число меньше 10 – на "BOOM!". Если число четное, мы выбрасываем его из нашего списка. Для удобства мы поместим выражение в функцию, чтобы потом легко повторно его использовать.
boomBangs xs = [ if x < 10 then "BOOM!" else "BANG!" | x <- xs, odd x]
Последняя часть описания – предикат. Функция odd возвращает True на нечётных числах и False на чётных. Элемент включается в список только если все предикаты возвращают True.
ghci> boomBangs [7..13] ["BOOM!","BOOM!","BANG!","BANG!"]
Мы можем использовать несколько предикатов. Если потребовалось бы получить все числа от 10 до 20, кроме 13, 15 и 19, тогда бы мы написали:
ghci> [ x | x <- [10..20], x /= 13, x /= 15, x /= 19] [10,11,12,14,16,17,18,20]
Мы можем не только написать несколько предикатов в «выражениях списков» (элемент должен удовлетворять всем предикатам, чтобы быть включённым в результирующий список), но также и выбирать элементы из нескольких списков. При выборе элементов из нескольких списков выражения перебирают все комбинации из данных списков и затем объединяют их по производящей функции, которую мы указали. Список, произведённый выражением из двух списков длины 4, будет иметь длину 16, если мы не фильтруем выходной список. Допустим, у нас есть два списка, [2,5,10] и [8,10,11] , и мы решили получить результат всех возможных комбинаций чисел из этих списков, вот что мы сделаем:
ghci> [ x*y | x <- [2,5,10], y <- [8,10,11]] [16,20,22,40,50,55,80,100,110]
Как и ожидалось, длина нового списка равна 9. Что если бы нам потребовались все возможные произведения, которые больше 50?
ghci> [ x*y | x <- [2,5,10], y <- [8,10,11], x*y > 50] [55,80,100,110]
Как насчет списка, объединяющего элементы списка прилагательных с элементами списка существительных… с довольно забавным результатом.
ghci> let nouns = ["hobo","frog","pope"] ghci> let adjectives = ["lazy","grouchy","scheming"] ghci> [adjective ++ " " ++ noun | adjective <- adjectives, noun <- nouns] ["lazy hobo","lazy frog","lazy pope","grouchy hobo","grouchy frog", "grouchy pope","scheming hobo","scheming frog","scheming pope"]
Придумал! Давайте напишем нашу собственную версию функции length! Мы назовём её length'.
length' xs = sum [1 | _ <- xs]
_ означает, что нам не важно, что будет получено из списка, так что вместо того, чтобы писать имя переменной, которое мы никогда не будем использовать, мы просто пишем _ Эта функция заменяет каждый элемент списка на 1 , а затем суммирует получившийся список. Это означает, что результирующая сумма и будет длиной нашего списка.
Просто дружеское напоминание: поскольку строки – это списки, мы можем использовать «выражение списков» для обработки и производства строк. Вот функция, которая принимает строку и удаляет из неё всё, кроме букв верхнего регистра:
removeNonUppercase st = [ c | c <- st, c `elem` ['A'..'Z']]
Проверяем:
ghci> removeNonUppercase "Hahaha! Ahahaha!" "HA" ghci> removeNonUppercase "IdontLIKEFROGS" "ILIKEFROGS"
Тут всю работу делает предикат. Он говорит, что символ будет включён в новый список только, если этот элемент – элемент списка ['A'..'Z']. Вложенные «выражения списков» также возможны, если вы работаете со списками, содержащими списки. Допустим, список содержит несколько списков чисел. Давайте удалим все нечётные числа, не разворачивая список.
ghci> let xxs = [[1,3,5,2,3,1,2,4,5],[1,2,3,4,5,6,7,8,9],[1,2,4,2,1,6,3,1,3,2,3,6]] ghci> [ [ x | x <- xs, even x ] | xs <- xxs] [[2,2,4],[2,4,6,8],[2,4,2,6,2,6]]
Вы можете писать «выражение списка» в несколько строк. Поэтому, если вы не в ghci, лучше разбить длинные «выражения списков» в несколько строк, особенно если они вложенные.
Кортежи

В некотором смысле, кортежи подобны спискам: они позволяют хранить несколько значений, как единый элемент. Однако, есть несколько фундаментальных различий. Список чисел – это список чисел. Это его тип, и неважно, находится ли в нём одно число или бесконечное количество. Однако, кортежи используются, когда вы точно знаете, сколько значений вы хотите собрать вместе, и их тип зависит от количества и типа компонентов. Они обозначаются скобками, а их компоненты разделяются запятыми.
Другое ключевое различие – то, что они не должны быть гомогенными. В отличие от списков, кортеж может содержать комбинацию разных типов.
Подумайте о том, как бы мы представили двумерный вектор в Haskell. Один вариант – использовать список. Это могло бы сработать, но что если мы хотели бы поместить несколько векторов в список для представления точек фигуры на двумерной плоскости? Мы могли бы сделать что-то вроде [[1,2],[8,11],[4,5]]. Проблема такого подхода в том, что Haskell не запретит задать таким образом что-нибудь вроде [[1,2],[8,11,5],[4,5]], поскольку это будет по-прежнему список списков с числами, но теперь это становится бессмысленным. Но кортеж с двумя элементами (также называемый парой) имеет свой собственный тип, а это значит, что список не может содержать несколько пар, а потом – тройку (кортеж размера 3), так что давайте воспользуемся этим вариантом. Вместо заключения векторов в квадратные скобки мы используем круглые: [(1,2),(8,11),(4,5)]. А что если бы мы попытались создать такую фигуру как [(1,2),(8,11,5),(4,5)]? Значит, мы бы получили такую ошибку:
Couldn't match expected type `(t, t1)' against inferred type `(t2, t3, t4)' In the expression: (8, 11, 5) In the expression: [(1, 2), (8, 11, 5), (4, 5)] In the definition of `it': it = [(1, 2), (8, 11, 5), (4, 5)]
Это нам говорит, что мы попытались использовать пару и тройку в одном списке, чего не должно быть. Также, нельзя сделать список подобно [(1,2),("One",2)] , потому что первый элемент списка – это пара чисел, а второй – пара, состоящая из строки и числа. Кортежи, также, можно использовать для представления широкого диапазона данных. Например, если бы мы хотели представить чьё-то имя и возраст в Haskell, мы могли бы воспользоваться тройкой: ("Christopher", "Walken", 55). Как видно из этого примера, кортежи тоже могут содержать списки.
Используйте кортежи, когда вы знаете заранее из скольки элементов будет состоять некая часть данных. Кортежи гораздо менее гибки, поскольку количество и тип элементов образуют тип кортежа, так что вы не можете написать общую функцию, чтобы добавить элемент в кортеж – вам нужно написать функцию, чтобы добавить его к паре, функцию, чтобы добавить его к тройке, функцию, чтобы добавить его к четвёрке и т.д.
Несмотря на то, что есть списки с одним элементом, не бывает кортежей с одним компонентом. Это неудивительно, если подумать. Кортеж с единственным элементом был бы просто значением, которое он содержит, и таким образом, не давал бы нам никаких дополнительных возможностей.
Как и списки, кортежи можно сравнивать друг с другом, если можно сравнивать их компоненты. Однако, вы не сможете сравнить кортежи разных размеров, хотя сможете сравнить списки разных размеров. Две полезные функции для работы с парами:
fst принимает пару и возвращает её первый компонент.
ghci> fst (8,11)
8
ghci> fst ("Wow", False)
"Wow"
snd принимает пару и возвращает её второй компонент. Неожиданно!
ghci> snd (8,11)
11
ghci> snd ("Wow", False)
False
Замечательная функция, производящая список пар, – zip. Она принимает два списка и соединяет их в один список, объединяя соответствующие элементы в пары. Это очень простая, но крайне полезная функция. Особенно она полезна, когда вы хотите объединить два списка вместе или обойти два списка одновременно. Вот демонстрация:
ghci> zip [1,2,3,4,5] [5,5,5,5,5] [(1,5),(2,5),(3,5),(4,5),(5,5)] ghci> zip [1 .. 5] ["one", "two", "three", "four", "five"] [(1,"one"),(2,"two"),(3,"three"),(4,"four"),(5,"five")]
Функция спаривает элементы и производит новый список. Первый элемент идёт с первым, второй – со вторым и т.д. Обратите на это внимание, поскольку пары могут содержать разные типы, zip может принять два списка, содержащих разные типы, и объединить их. А что произойдет, если длина списков не совпадает?
ghci> zip [5,3,2,6,2,7,2,5,4,6,6] ["im","a","turtle"] [(5,"im"),(3,"a"),(2,"turtle")]
Более длинный список просто обрезается до длины более короткого. Поскольку Haskell ленив, мы можем объединить бесконечный список с конечным:
ghci> zip [1..] ["apple", "orange", "cherry", "mango"] [(1,"apple"),(2,"orange"),(3,"cherry"),(4,"mango")]
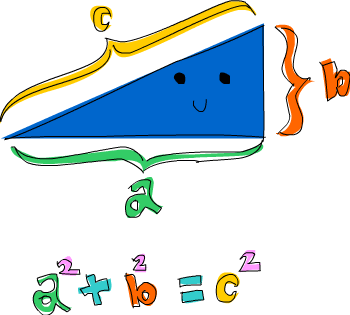
Вот задача, которая сочетает кортежи и «выражение списка»: какие прямоугольные треугольники имеют целые длины сторон не более 10 и периметр 24? Сначала давайте попробуем сгенерировать все треугольники со сторонами, меньшими либо равными 10:
ghci> let triangles = [ (a,b,c) | c <- [1..10], b <- [1..10], a <- [1..10] ]
Мы просто собираем вместе три списка, и наша производящая функция объединяет их в тройки. Если вы введёте triangles в ghci, то получите список всех возможных треугольников со сторонам не больше 10. Теперь давайте добавим условие, что все они должны быть прямоугольными треугольниками. Мы также модифицируем эту функцию, приняв во внимание, что сторона b не больше гипотенузы и сторона a не больше стороны b.
ghci> let rightTriangles = [ (a,b,c) | c <- [1..10], b <- [1..c], a <- [1..b], a^2 + b^2 == c^2]
Почти закончили. Теперь давайте модифицируем функцию, чтобы получить треугольники, периметр которых равен 24.
ghci> let rightTriangles' = [ (a,b,c) | c <- [1..10], b <- [1..c], a <- [1..b], a^2 + b^2 == c^2, a+b+c == 24] ghci> rightTriangles' [(6,8,10)]
Вот и ответ! Это общий шаблон в функиональном программировании. Вы берете начальный набор решений и затем применяете преобразования и фильтруете их, пока не получите результат.